

Data classification involves analysing and sorting data into one or more 'classes', based on the type, content, age and other attributes of the item. This is used to make decisions about what to do next with that information, to protect it or extract value from it for other business activities.
At the simplest level, it's an approach to sort large volumes of data into 'types', as the starting point to managing it better. The classification process often applies a 'label' to the file to allow follow-up activity to move, secure, or act on that information.
A piece of data can belong to multiple 'classes' that might make sense for a company as it looks to manage information better. For example, imagine a PDF document stored in an old file share within an organisation. If a human read the document then it would be obvious that this document is a correspondence letter written to a customer. The letter could contain all sorts of information, so it's very possible that multiple classification labels might then be applied to that document, depending on what the organisation's objectives are for that type of data.
Why is data classification important?
Organisations are drowning in the volume of data and documents that they are generating, storing and having to retain. 'Unstructured data' (such as documents and emails) is particularly difficult to manage because it's created by human interaction. Up to 80% of organisational data is unstructured and it's growing at a staggering rate. This translates into tens of millions or even billions of items that we need a way to understand and act on to protect and power the organisation and the people it serves.
The process of data classification at scale within an organisation is therefore an increasingly valuable activity as a pre-cursor to acting on data. That example letter we mentioned above might form part of a communication chain with them that it would be valuable to recall or use in future. It may contain sensitive, private or even special category health information that we have an obligation to safeguard on behalf of the customer. Possibly it contains commercially sensitive information that might expose the business to risk in future.
Every company is a 'data company' these days. Increasingly, organisations are realising that they must be more proactive in tackling their legacy data, to understand it and then act on it.
Danger! Data classification can be inaccurate
It all sounds great, but as with many things in life, data classification is far from easy when it comes to automating the process to cover all of the classes of things you might want to apply.
Some information is very easy to spot with confidence, and in those cases it's very easy to classify a document or a field in a database at scale and without human intervention. A good example of straight-forward data classification include any data that contains a 'regular expression', such as a valid credit card number (which follows a set pattern known as the Luhn algorithm). If you wanted to classify any data that contains a credit card number then that is relatively easy to do with data classification and would be between 96-98% accurate.
The problem is, classifying data accurately using automation is much less straightforward when intelligence is required to understand the document. This is where machine learning and AI comes in - to increase the accuracy of classification to the point where a false-positive is unlikely. Most of our customers look for an accuracy of at least 80% in order to allow a machine to classify data at volume and automatically trigger action on the item.
A good example of difficult information to classify might be documents or correspondence containing Personal Health Information (PHI) relating to an individual, where it's important to accurately identify anything in a document that includes personal information relating to the health or medical status of an individual. PHI is considered a 'special category' form of personal information, so spotting that amongst vital correspondence with patients whilst also protecting it, is a difficult challenge for classification software.
Achieving even 80%+ classification accuracy can be a challenge, and of course it's important to remember that even when you've found and classified 80% of the documents that should be in that class, it means you've missed 20% of them - each of which could be a risk and may never be identified, protected or used to drive value.
This lack of certainty around classification is one of the reasons that you can't rely on classification to help you know your data. It's also the reason we advocate building an 'index of everything' with Exonar Reveal, to ensure all of your data can be found.
Every organisation's data is different
The next challenge in classification is to take account of the highly bespoke nature of data found within different companies. While classification of some information (like credit card data) is standard and straightforward, we often work closely with customers to find and classify information that is highly bespoke to their business, either as part of a data migration project or sorting data that's been acquired through acquisition of another company.
Given that every organisation's data is different, we believe that the first step of proper classification of data is to gain true visibility of your data first, to understand it at a macro-level before you are in a position to define the classes of data you possess, then build classification rules, or train machine learning algorithms, to classify and label your information, or pass it along to remediation systems or other business processes.
Essentially it's like emptying your cluttered garage at home - there's lots in there but because it's so full, you can't actually step inside to see what's in there. If you were planning to classify the contents of your garage with post-it labels before holding a garage sale, then you'll need to manually discover and understand your possessions first, before deciding what to do.

So you start by emptying the garage, you place similar objects in neat piles on the driveway, organised so that you can then deal with those in the best way. Now you see the contents you can see that certain things should be grouped as similar, so that you'll treat them in the same way. Only a human (or a trained or intelligent machine) would be able to define those classifications and make those decisions.
Once you have the contents of your garage out in the open and you have your neat piles of belongings organised in the most logical way, then you can apply your post-it notes and you know exactly what to write on them too and what you have planned for each class of contents - keep, sell, donate, or discard.
If your organisation's data estate is analogous to the 'garage full of junk', the first step needs to be to discover and gain visibility of everything you have - so you know how to classify it.
First, discover and understand your data
Lots of companies look to plug classification software into their data, use pre-determined classification rules (applicable to all organisations) and then hope that this is sufficient to accurately classify their data. At Exonar, based on experience helping customers of all types, we believe this approach will prove, at best, around 20% effective in terms of understanding your data.
We know this because, as described above, while some 'out of the box' classification is relatively fool-proof and accurate, the rest of your data will be much harder to process and make sense of, unless you take the time to understand the data first and ideally, index it all first.
Indexing your data to give a single view of everything you have, was once impossible, but can now be achieved through our world-leading product, Exonar Reveal. We provide a 'Google like' ability to instantly search for anything, right down to text within documents. We then allow users to refine that search to pin-point specific types of risky or valuable information and bring it into view. By doing this, we are able to define very accurate classifications. Better still, we can provide a set of appropriate documents to train a machine learning algorithm such that any future information like this can be accurately identified through automatic classification.
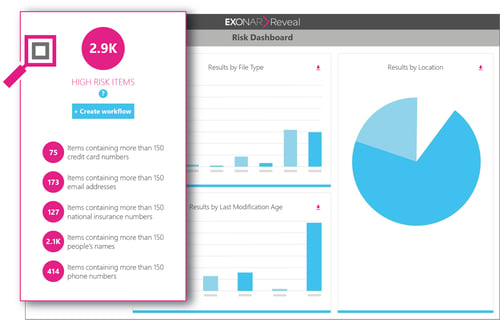
While we can identify value and risk more accurately with a view to classifying such information, we can also accurately identify redundant, obsolete or trivial data that can be deleted.
Finally, as part of our data enrichment process we can identify duplicated files and documents, which regularly accounts for at least 40% of data stored in file shares, email systems and the like. These duplicates can be dealt with and removed, helping reduce data footprints, costs and also the resulting CO2 emissions that over-use of digital storage generates.
You can find out more about Exonar Reveal here.
Three key things to remember about data classification.
To summarise the key points around data classification, we recommend taking away the following points about data classification:
1. Data Classification is a powerful way to organise your data, before acting on it
It is a way of analysing and sorting large volumes of unstructured and structured data within organisations, by attributing items with one or more classes.
2. Accuracy of classification is a significant challenge, except in specific cases
Some data, such as specific types of PII, are very easy to identify and classify against, with high levels (96%+) of confidence and accuracy. However, achieving broader classifications of information without human interaction is much harder and requires machine-learning or AI to drive confidence in classification in an automated manner, at scale.
3. Build an 'index of everything' before attempting to classify data
We strongly recommend discovering and understanding your data before embarking on building the rules to classify it. Software that classifies documents during scanning are prone to missing information and can only act on defined classifications at time of scanning. Exonar Reveal's live index of data enables classification of data at any time, to find any previously undefined type or class of data. It is then possible to drive workflows to act on this information.
4. Classification of data doesn't replace full visibility of your data
Data classification is great for understanding which 'box' to place data in at volume, and then enables action to be taken at an item level. While this However to be less useful for valuable data, as it simply records the classification and doesn't extract the information itself. This is fine for simple privacy classification or removing obvious sensitive data, but leaves much of the value in data unexposed.
We hope this article has been useful. Below you can find a table with examples of types of data that our customers look to classify, and what their labels might look like.
Remember to get in touch if you want to ask any questions or find out more about Exonar Reveal!
Reference: Examples of common data classifications
There are a number of common classifications that organisations might look to define and then label their data with, so that it can be managed efficiently and appropriately.
Note that the output of classification is often to 'label' the file or document for follow-up intervention or protection through another process, we have included examples of the kind of labels you would expect to find on classified documentation. These labels could be applied while other processes or systems are triggered to deal with the data.
| Category | Interest | Example classification labels |
|
Customer Personally Identifiable information (PII) Employee Personally Identifiable Information |
To protect individual privacy and comply with regulation. Note that some PII, such as national identity numbers or telephone numbers, need to be defined by country or region. |
"contains PII" "contains addresses" "contains phone numbers" "contains NI numbers" "contains email addresses" "Privacy data" "contains passport numbers" "PII Audit 2019" "Over-retained PII - delete" |
| Credit Card details |
Copies of credit card information should not exist outside of highly secured systems in designated locations Concentrations of valid credit card information represents high risk of breach |
"Contains Credit Card Data" "Credit Cards" |
| Personal Health Information (PHI) | Any health or medical information relating to individuals is considered "special category" PII and requires extra protection |
"PHI Sensitive" "Sensitive Health Records" "Patient Health Records" |
| Genetic Data | Genetic data when linked to an individual is regarded as special category PII |
"Personal Data - Genetic" "Genetic Data - sensitive" |
| Ethnic, Racial, Religious or philosophical beliefs | Considered special category personal information as it could create significant risks to the individual’s fundamental rights and freedoms |
"contains ethnicity" "contains religions" "contains ethnicity" "contains sensitive associations" |
| Biometric data | Includes fingerprints, voice recognition, facial recognition data |
"biometric data" "personal biometric data" |
| Commercial Classifications | classification of documents according to their commercial sensitivity |
"Strictly Confidential" "Company Confidential" "Company Sensitive" "group association" |
| Customer Sentiment | records customer sentiment or preference for use in understanding customer behaviours or perceptions |
"Marketing Interaction" "Customer Insight - complaint" "Consumer Insight - Pref1" "Customer Complaint" "Client Feedback" |
| Valuable Research Data | Research-based departments or organisations looking to extract and aggregate scientific, Engineering or manufacturing knowledge within the organisation, for various purposes |
"Project Alpha Research" "Research Stage A Results" "Research Trial Results AB19" "R&D Project Gamma" "Omega Test Phase Data" |
Want to try Exonar on your data?
Get a FREE 2-week test drive.

Subscribe to Our Newsletter
Get the latest product updates, company news, and insight delivered right to your inbox.